
Introduction
- 现有的行人重识别研究都是基于裁剪好的行人照片来进行,而实际应用中,摄像机获取的都是全景图像,如果直接使用这样的图像去做重识别,效果会比裁剪过的输入差得多。在行人重识别中面临的光照、遮挡、背景干扰等问题也会得到放大。如果要缩小现有研究与应用之间的差距,就需要将行人检测和行人重识别结合起来,而不是作为两个单独的问题。

Method
论文提出了一种使用一个卷积神经网络联合处理行人检测和行人重识别两个子任务的深度学习框架。网络接受完整的原始图像作为输入,通过骨干网络(stem CNN)获取特征图,在特征图上使用行人提案网络(pedestrian proposal net)预测候选区域,通过RoI-Polling提取每一个区域的特征交由判别网络(identification net)判别身份。
在训练阶段,根据特征向量,使用OIM损失等一系列损失来监督判别网络的学习;在推断阶段,使用Gallery与目标行人之间的距离排序确定身份。
该框架的示意图如下:
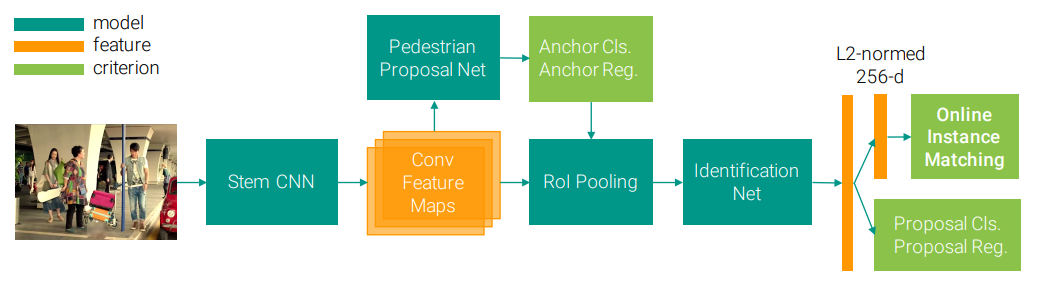
Model Structure
论文采用ResNet50作为CNN的基本架构,使用conv1至conv4_3部分作为stem CNN,经过stem CNN,会生成一张大小为原图、维度为1024的特征图。
类似Faster R-CNN,stem CNN之后是一个的卷积层进行一次特征的转换,随后在特征图上的每个位置通过9个anchors和1个Softmax分类器来预测行人,通过一个线性回归器进行BB回归,最后采用NMS保留128个候选框作为最终的proposals。
对于每个proposal,使用RoI Pooling从特征图里获取一个的特征图,将其送入ResNet后续的conv4_4至conv5_3层,通过Global Average Pooling获取2048维的特征向量。
此后,网络分成两个任务分支,其中一个分支,将特征向量投影到经过L2正则化的256维空间,计算与目标行人的余弦相似度;另一个分支考虑到pedestrian proposal net中生成的提案存在误分类或不对齐的可能性,使用Softmax分类器和线性回归器来拒绝非行人提案并修正边框。
Online Instance Matching Loss
假定训练集中存在个不同身份的行人,若某一proposal匹配到某一目标行人,称该proposal为labeled identity,并为其确定对应的身份;若proposal确为行人,但不是目标行人,称为unlabeled identity;对于其他的非行人proposal,称为background clutter。

类似三元损失,OIM也希望缩小相同身份的人之间的距离,增大不同身份的人之间的距离。OIM使用记忆体去存储所有任务的特征,通过在线逼近(online approximation)进行优化。具体的操作如下:
对于labeled identity,其特征被记作,维护一个查找表用于记录所有身份的特征信息,在前向传播中,通过计算来计算样本和所有身份之间的余弦相似度;在反向传播过程中更新对应身份对应的行。
对于unlabeled identity,可以视为负样本,其特征被记作,使用一个循环队列保存其特征,其中为队列长度。每一轮迭代过后,将新的特征向量压入队列,并剔除过期的向量。
基于查找表和循环队列这两个记忆体,可以通过Softmax函数定义某个labeled identity的特征属于第个身份的概率或某个unlabeled identity的特征属于第类unlabelled identity的概率如下
OIM损失函数的优化目标是使得对数似然函数的期望最大化,即
Paper Information
Xiao T, Li S, Wang B, et al. Joint detection and identification feature learning for person search[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3415-3424.